1. Scrapy简介 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。 其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试 Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下
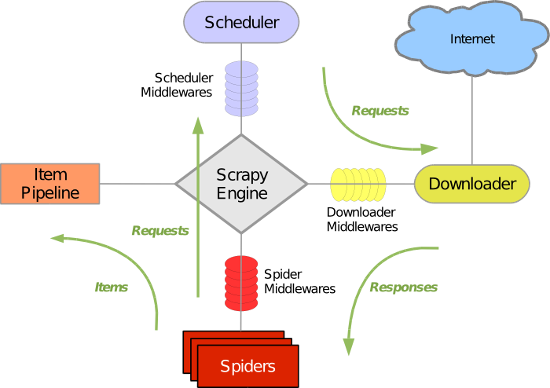
Scrapy主要包括了以下组件:
(1)引擎(Scrapy): 用来处理整个系统的数据流处理, 触发事务(框架核心)
(2)调度器(Scheduler): 用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
(3)下载器(Downloader): 用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
(4)爬虫(Spiders): 爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
项目管道(Pipeline): 负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
(5)下载器中间件(Downloader Middlewares): 位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
(6)爬虫中间件(Spider Middlewares): 介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
(7)调度中间件(Scheduler Middewares): 介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
首先,引擎从调度器中取出一个链接(URL)用于接下来的抓取 引擎把URL封装成一个请求(Request)传给下载器,下载器把资源下载下来,并封装成应答包(Response) 然后,爬虫解析Response 若是解析出实体(Item),则交给实体管道进行进一步的处理。 若是解析出的是链接(URL),则把URL交给Scheduler等待抓取
2. 安装Scrapy 使用以下命令:
sudo pip install virtualenv #安装虚拟环境工具
virtualenv ENV #创建一个虚拟环境目录
source ./ENV/bin/active #激活虚拟环境
pip install Scrapy
#验证是否安装成功
pip list
#输出如下
cffi (0.8.6)
cryptography (0.6.1)
cssselect (0.9.1)
lxml (3.4.1)
pip (1.5.6)
pycparser (2.10)
pyOpenSSL (0.14)
queuelib (1.2.2)
Scrapy (0.24.4)
setuptools (3.6)
six (1.8.0)
Twisted (14.0.2)
w3lib (1.10.0)
wsgiref (0.1.2)
zope.interface (4.1.1)
更多虚拟环境的操作可以查看我的博文
3. Scrapy Tutorial 在抓取之前, 你需要新建一个Scrapy工程. 进入一个你想用来保存代码的目录,然后执行:
$ scrapy startproject tutorial
这个命令会在当前目录下创建一个新目录 tutorial, 它的结构如下:
.
├── scrapy.cfg
└── tutorial
├── __init__.py
├── items.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py
这些文件主要是:
(1)scrapy.cfg: 项目配置文件 (2)tutorial/: 项目python模块, 之后您将在此加入代码 (3)tutorial/items.py: 项目items文件 (4)tutorial/pipelines.py: 项目管道文件 (5)tutorial/settings.py: 项目配置文件 (6)tutorial/spiders: 放置spider的目录
3.1. 定义Item Items是将要装载抓取的数据的容器,它工作方式像 python 里面的字典,但它提供更多的保护,比如对未定义的字段填充以防止拼写错误
通过创建scrapy.Item类, 并且定义类型为 scrapy.Field 的类属性来声明一个Item. 我们通过将需要的item模型化,来控制从 dmoz.org 获得的站点数据,比如我们要获得站点的名字,url 和网站描述,我们定义这三种属性的域。在 tutorial 目录下的 items.py 文件编辑
from scrapy.item import Item, Field
class DmozItem(Item):
# define the fields for your item here like:
name = Field()
description = Field()
url = Field()
3.2. 编写Spider Spider 是用户编写的类, 用于从一个域(或域组)中抓取信息, 定义了用于下载的URL的初步列表, 如何跟踪链接,以及如何来解析这些网页的内容用于提取items。
要建立一个 Spider,继承 scrapy.Spider 基类,并确定三个主要的、强制的属性:
name:爬虫的识别名,它必须是唯一的,在不同的爬虫中你必须定义不同的名字. start_urls:包含了Spider在启动时进行爬取的url列表。因此,第一个被获取到的页面将是其中之一。后续的URL则从初始的URL获取到的数据中提取。我们可以利用正则表达式定义和过滤需要进行跟进的链接。 parse():是spider的一个方法。被调用时,每个初始URL完成下载后生成的 Response 对象将会作为唯一的参数传递给该函数。该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的 Request 对象。 这个方法负责解析返回的数据、匹配抓取的数据(解析为 item )并跟踪更多的 URL。 在 /tutorial/tutorial/spiders 目录下创建 dmoz_spider.py
import scrapy
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
]
def parse(self, response):
filename = response.url.split("/")[-2]
with open(filename, 'wb') as f:
f.write(response.body)
3.3. 爬取 当前项目结构
├── scrapy.cfg
└── tutorial
├── __init__.py
├── items.py
├── pipelines.py
├── settings.py
└── spiders
├── __init__.py
└── dmoz_spider.py
到项目根目录, 然后运行命令:
$ scrapy crawl dmoz
2014-12-15 09:30:59+0800 [scrapy] INFO: Scrapy 0.24.4 started (bot: tutorial)
2014-12-15 09:30:59+0800 [scrapy] INFO: Optional features available: ssl, http11
2014-12-15 09:30:59+0800 [scrapy] INFO: Overridden settings: {'NEWSPIDER_MODULE': 'tutorial.spiders', 'SPIDER_MODULES': ['tutorial.spiders'], 'BOT_NAME': 'tutorial'}
2014-12-15 09:30:59+0800 [scrapy] INFO: Enabled extensions: LogStats, TelnetConsole, CloseSpider, WebService, CoreStats, SpiderState
2014-12-15 09:30:59+0800 [scrapy] INFO: Enabled downloader middlewares: HttpAuthMiddleware, DownloadTimeoutMiddleware, UserAgentMiddleware, RetryMiddleware, DefaultHeadersMiddleware, MetaRefreshMiddleware, HttpCompressionMiddleware, RedirectMiddleware, CookiesMiddleware, ChunkedTransferMiddleware, DownloaderStats
2014-12-15 09:30:59+0800 [scrapy] INFO: Enabled spider middlewares: HttpErrorMiddleware, OffsiteMiddleware, RefererMiddleware, UrlLengthMiddleware, DepthMiddleware
2014-12-15 09:30:59+0800 [scrapy] INFO: Enabled item pipelines:
2014-12-15 09:30:59+0800 [dmoz] INFO: Spider opened
2014-12-15 09:30:59+0800 [dmoz] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2014-12-15 09:30:59+0800 [scrapy] DEBUG: Telnet console listening on 127.0.0.1:6023
2014-12-15 09:30:59+0800 [scrapy] DEBUG: Web service listening on 127.0.0.1:6080
2014-12-15 09:31:00+0800 [dmoz] DEBUG: Crawled (200) <GET http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/> (referer: None)
2014-12-15 09:31:00+0800 [dmoz] DEBUG: Crawled (200) <GET http://www.dmoz.org/Computers/Programming/Languages/Python/Books/> (referer: None)
2014-12-15 09:31:00+0800 [dmoz] INFO: Closing spider (finished)
2014-12-15 09:31:00+0800 [dmoz] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 516,
'downloader/request_count': 2,
'downloader/request_method_count/GET': 2,
'downloader/response_bytes': 16338,
'downloader/response_count': 2,
'downloader/response_status_count/200': 2,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2014, 12, 15, 1, 31, 0, 666214),
'log_count/DEBUG': 4,
'log_count/INFO': 7,
'response_received_count': 2,
'scheduler/dequeued': 2,
'scheduler/dequeued/memory': 2,
'scheduler/enqueued': 2,
'scheduler/enqueued/memory': 2,
'start_time': datetime.datetime(2014, 12, 15, 1, 30, 59, 533207)}
2014-12-15 09:31:00+0800 [dmoz] INFO: Spider closed (finished)
3.4. 提取Items 3.4.1. 介绍Selector 从网页中提取数据有很多方法。Scrapy使用了一种基于 XPath 或者 CSS 表达式机制: Scrapy Selectors
出XPath表达式的例子及对应的含义:
- /html/head/title: 选择HTML文档中 <head> 标签内的 <title> 元素
- /html/head/title/text(): 选择 <title> 元素内的文本
- //td: 选择所有的 <td> 元素
- //div[@class="mine"]: 选择所有具有class="mine" 属性的 div 元素
等多强大的功能使用可以查看XPath tutorial
为了方便使用 XPaths,Scrapy 提供 Selector 类, 有四种方法 :
- xpath():返回selectors列表, 每一个selector表示一个xpath参数表达式选择的节点.
- css() : 返回selectors列表, 每一个selector表示CSS参数表达式选择的节点
- extract():返回一个unicode字符串,该字符串为XPath选择器返回的数据
- re(): 返回unicode字符串列表,字符串作为参数由正则表达式提取出来
3.4.2. 取出数据
- 首先使用谷歌浏览器开发者工具, 查看网站源码, 来看自己需要取出的数据形式(这种方法比较麻烦), 更简单的方法是直接对感兴趣的东西右键审查元素, 可以直接查看网站源码
在查看网站源码后, 网站信息在第二个<ul>内
<ul class="directory-url" style="margin-left:0;">
<li><a href="http://www.pearsonhighered.com/educator/academic/product/0,,0130260363,00%2Ben-USS_01DBC.html" class="listinglink">Core Python Programming</a>
- By Wesley J. Chun; Prentice Hall PTR, 2001, ISBN 0130260363. For experienced developers to improve extant skills; professional level examples. Starts by introducing syntax, objects, error handling, functions, classes, built-ins. [Prentice Hall]
<div class="flag"><a href="/public/flag?cat=Computers%2FProgramming%2FLanguages%2FPython%2FBooks&url=http%3A%2F%2Fwww.pearsonhighered.com%2Feducator%2Facademic%2Fproduct%2F0%2C%2C0130260363%2C00%252Ben-USS_01DBC.html"><img src="/img/flag.png" alt="[!]" title="report an issue with this listing"></a></div>
</li>
...省略部分...
</ul>
那么就可以通过一下方式进行提取数据
#通过如下命令选择每个在网站中的 <li> 元素:
sel.xpath('//ul/li')
#网站描述:
sel.xpath('//ul/li/text()').extract()
#网站标题:
sel.xpath('//ul/li/a/text()').extract()
#网站链接:
sel.xpath('//ul/li/a/@href').extract()
如前所述,每个 xpath() 调用返回一个 selectors 列表,所以我们可以结合 xpath() 去挖掘更深的节点。我们将会用到这些特性,所以:
for sel in response.xpath('//ul/li')
title = sel.xpath('a/text()').extract()
link = sel.xpath('a/@href').extract()
desc = sel.xpath('text()').extract()
print title, link, desc
在已有的爬虫文件中修改代码
import scrapy
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
]
def parse(self, response):
for sel in response.xpath('//ul/li'):
title = sel.xpath('a/text()').extract()
link = sel.xpath('a/@href').extract()
desc = sel.xpath('text()').extract()
print title, link, desc
3.4.3. 使用item Item对象是自定义的python字典,可以使用标准的字典语法来获取到其每个字段的值(字段即是我们之前用Field赋值的属性)
>>> item = DmozItem()
>>> item['title'] = 'Example title'
>>> item['title']
'Example title'
一般来说,Spider将会将爬取到的数据以 Item 对象返回, 最后修改爬虫类,使用 Item 来保存数据,代码如下
from scrapy.spider import Spider
from scrapy.selector import Selector
from tutorial.items import DmozItem
class DmozSpider(Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/",
]
def parse(self, response):
sel = Selector(response)
sites = sel.xpath('//ul[@class="directory-url"]/li')
items = []
for site in sites:
item = DmozItem()
item['name'] = site.xpath('a/text()').extract()
item['url'] = site.xpath('a/@href').extract()
item['description'] = site.xpath('text()').re('-\s[^\n]*\\r')
items.append(item)
return items
3.5. 使用Item Pipeline 当Item在Spider中被收集之后,它将会被传递到Item Pipeline,一些组件会按照一定的顺序执行对Item的处理。 每个item pipeline组件(有时称之为ItemPipeline)是实现了简单方法的Python类。他们接收到Item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或是被丢弃而不再进行处理。 以下是item pipeline的一些典型应用:
- 清理HTML数据
- 验证爬取的数据(检查item包含某些字段)
- 查重(并丢弃)
- 将爬取结果保存,如保存到数据库、XML、JSON等文件中
编写你自己的item pipeline很简单,每个item pipeline组件是一个独立的Python类,同时必须实现以下方法:
(1)process_item(item, spider) #每个item pipeline组件都需要调用该方法,这个方法必须返回一个 Item (或任何继承类)对象,或是抛出 DropItem异常,被丢弃的item将不会被之后的pipeline组件所处理。
#参数:
item: 由 parse 方法返回的 Item 对象(Item对象)
spider: 抓取到这个 Item 对象对应的爬虫对象(Spider对象)
(2)open_spider(spider) #当spider被开启时,这个方法被调用。
#参数:
spider : (Spider object) – 被开启的spider
(3)close_spider(spider) #当spider被关闭时,这个方法被调用,可以再爬虫关闭后进行相应的数据处理。
#参数:
spider : (Spider object) – 被关闭的spider
为JSON文件编写一个items
from scrapy.exceptions import DropItem
class TutorialPipeline(object):
# put all words in lowercase
words_to_filter = ['politics', 'religion']
def process_item(self, item, spider):
for word in self.words_to_filter:
if word in unicode(item['description']).lower():
raise DropItem("Contains forbidden word: %s" % word)
else:
return item
在 settings.py 中设置ITEM_PIPELINES激活item pipeline,其默认为[]
ITEM_PIPELINES = {'tutorial.pipelines.FilterWordsPipeline': 1}
3.6. 存储数据 使用下面的命令存储为json文件格式
scrapy crawl dmoz -o items.json
4.示例 4.1最简单的spider(默认的Spider) 用实例属性start_urls中的URL构造Request对象 框架负责执行request 将request返回的response对象传递给parse方法做分析
简化后的源码:
class Spider(object_ref):
"""Base class for scrapy spiders. All spiders must inherit from this
class.
"""
name = None
def __init__(self, name=None, **kwargs):
if name is not None:
self.name = name
elif not getattr(self, 'name', None):
raise ValueError("%s must have a name" % type(self).__name__)
self.__dict__.update(kwargs)
if not hasattr(self, 'start_urls'):
self.start_urls = []
def start_requests(self):
for url in self.start_urls:
yield self.make_requests_from_url(url)
def make_requests_from_url(self, url):
return Request(url, dont_filter=True)
def parse(self, response):
raise NotImplementedError
BaseSpider = create_deprecated_class('BaseSpider', Spider)
一个回调函数返回多个request的例子
import scrapyfrom myproject.items import MyItemclass MySpider(scrapy.Spider):
name = 'example.com'
allowed_domains = ['example.com']
start_urls = [
'http://www.example.com/1.html',
'http://www.example.com/2.html',
'http://www.example.com/3.html',
]
def parse(self, response):
sel = scrapy.Selector(response)
for h3 in response.xpath('//h3').extract():
yield MyItem(title=h3)
for url in response.xpath('//a/@href').extract():
yield scrapy.Request(url, callback=self.parse)
构造一个Request对象只需两个参数: URL和回调函数
4.2CrawlSpider 通常我们需要在spider中决定:哪些网页上的链接需要跟进, 哪些网页到此为止,无需跟进里面的链接。CrawlSpider为我们提供了有用的抽象——Rule,使这类爬取任务变得简单。你只需在rule中告诉scrapy,哪些是需要跟进的。 回忆一下我们爬行mininova网站的spider.
class MininovaSpider(CrawlSpider):
name = 'mininova'
allowed_domains = ['mininova.org']
start_urls = ['http://www.mininova.org/yesterday']
rules = [Rule(LinkExtractor(allow=['/tor/\d+']), 'parse_torrent')]
def parse_torrent(self, response):
torrent = TorrentItem()
torrent['url'] = response.url
torrent['name'] = response.xpath("//h1/text()").extract()
torrent['description'] = response.xpath("//div[@id='description']").extract()
torrent['size'] = response.xpath("//div[@id='specifications']/p[2]/text()[2]").extract()
return torrent
上面代码中 rules的含义是:匹配/tor/\d+的URL返回的内容,交给parse_torrent处理,并且不再跟进response上的URL。 官方文档中也有个例子:
rules = (
# 提取匹配 'category.php' (但不匹配 'subsection.php') 的链接并跟进链接(没有callback意味着follow默认为True)
Rule(LinkExtractor(allow=('category\.php', ), deny=('subsection\.php', ))),
# 提取匹配 'item.php' 的链接并使用spider的parse_item方法进行分析
Rule(LinkExtractor(allow=('item\.php', )), callback='parse_item'),
)
除了Spider和CrawlSpider外,还有XMLFeedSpider, CSVFeedSpider, SitemapSpider