1、引言
在Python网络爬虫内容提取器一文我们详细讲解了核心部件:可插拔的内容提取器类gsExtractor。本文记录了确定gsExtractor的技术路线过程中所做的编程实验。这是第二部分,第一部分实验了用xslt方式一次性提取静态网页内容并转换成xml格式。留下了一个问题:javascript管理的动态内容怎样提取?那么本文就回答这个问题。
2、提取动态内容的技术部件
在上一篇python使用xslt提取网页数据中,要提取的内容是直接从网页的source code里拿到的。但是一些Ajax动态内容是在source code找不到的,就要找合适的程序库把异步或动态加载的内容加载上来,交给本项目的提取器进行提取。
python可以使用selenium执行javascript,selenium可以让浏览器自动加载页面,获取需要的数据。selenium自己不带浏览器,可以使用第三方浏览器如Firefox,Chrome等,也可以使用headless浏览器如PhantomJS在后台执行。
3、源代码和实验过程
假如我们要抓取京东手机页面的手机名称和价格(价格在网页源码是找不到的),如下图:
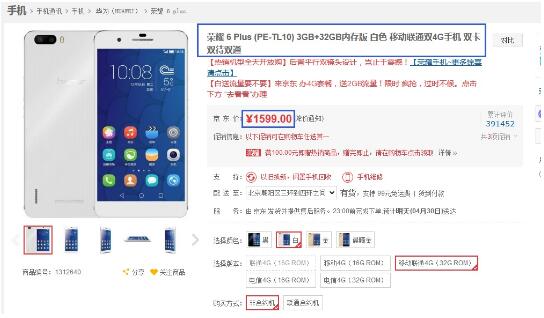
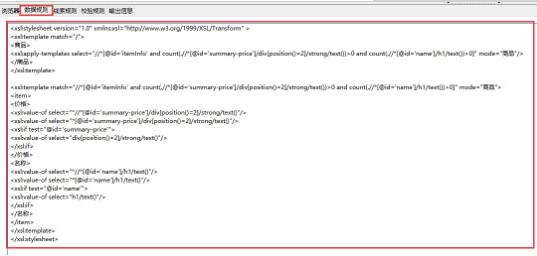
第一步:利用集搜客谋数台的直观标注功能,可以极快速度自动生成一个调试好的抓取规则,其实是一个标准的xslt程序,如下图,把生成的xslt程序拷贝到下面的程序中即可。注意:本文只是记录实验过程,实际系统中,将采用多种方式把xslt程序注入到内容提取器重。
第二步:执行如下代码(在windows10, python3.2下测试通过,源代码下载地址请见文章末尾GitHub),请注意:xslt是一个比较长的字符串,如果删除这个字符串,代码没有几行,足以见得Python之强大
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url = "http://item.jd.com/1312640.html"
# 下面的xslt是通过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform" >
<xsl:template match="/">
<商品>
<xsl:apply-templates select="//*[@id='itemInfo' and count(.//*[@id='summary-price']/div[position()=2]/strong/text())>0 and count(.//*[@id='name']/h1/text())>0]" mode="商品"/>
</商品>
</xsl:template>
<xsl:template match="//*[@id='itemInfo' and count(.//*[@id='summary-price']/div[position()=2]/strong/text())>0 and count(.//*[@id='name']/h1/text())>0]" mode="商品">
<item>
<价格>
<xsl:value-of select="*//*[@id='summary-price']/div[position()=2]/strong/text()"/>
<xsl:value-of select="*[@id='summary-price']/div[position()=2]/strong/text()"/>
<xsl:if test="@id='summary-price'">
<xsl:value-of select="div[position()=2]/strong/text()"/>
</xsl:if>
</价格>
<名称>
<xsl:value-of select="*//*[@id='name']/h1/text()"/>
<xsl:value-of select="*[@id='name']/h1/text()"/>
<xsl:if test="@id='name'">
<xsl:value-of select="h1/text()"/>
</xsl:if>
</名称>
</item>
</xsl:template>
</xsl:stylesheet>""")
# 使用webdriver.PhantomJS
browser = webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js得到整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取需要的字段
result_tree = transform(doc)
print(result_tree)
第三步:下图可以看到,网页中的手机名称和价格被正确抓取下来了

4、接下来阅读
至此,我们通过两篇文章演示怎样抓取静态和动态网页内容,都采用了xslt一次性将需要的内容从网页上提取出来,其实xslt是一个比较复杂的程序语言,如果手工编写xslt,那么还不如写成离散的xpath。如果这个xslt不是手工写出来的,而是程序自动生成的,这就有意义了,程序员再也不要花时间编写和调测抓取规则了,这是很费时费力的工作。下一篇《1分钟快速生成用于网页内容提取的xslt》将讲述怎样生成xslt。
5、集搜客GooSeeker开源代码下载源
1. GooSeeker开源Python网络爬虫GitHub源
6、文档修改历史
2016-05-26:V2.0,增补文字说明 2016-05-29:V2.1,增加第五章:源代码下载源,并更换github源的网址