爬取了下小猪短租的网站出租房信息但是输出的时候是这种:
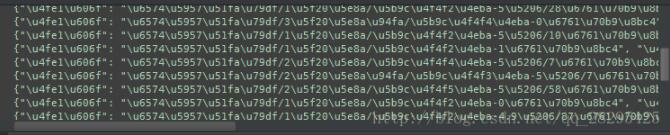
百度了下。python2.7在window上的编码确实是个坑
解决如下
如果是个字典的话要先将其转成字符串 导入json库
然后 这么输出(json.dumps(data).decode("unicode-escape"))
整个代码demo
# -*- coding: UTF-8 -*-
#小猪短租爬取
import requests
from bs4 import BeautifulSoup
import json
def get_xinxi(i):
url = 'http://cd.xiaozhu.com/search-duanzufang-p%d-0/' %i
html = requests.get(url)
soup = BeautifulSoup(html.content)
#获取地址
dizhis=soup.select(' div > a > span')
#获取价格
prices = soup.select(' span.result_price')
#获取简单信息
ems = soup.select(' div > em')
datas =[]
for dizhi,price,em in zip(dizhis,prices,ems):
data={
'价格':price.get_text(),
'信息':em.get_text().replace('\n','').replace(' ',''),
'地址':dizhi.get_text()
}
print(json.dumps(data).decode("unicode-escape"))
i=1
while(i<12):
get_xinxi(i)
i=i+1爬取了12页的信息
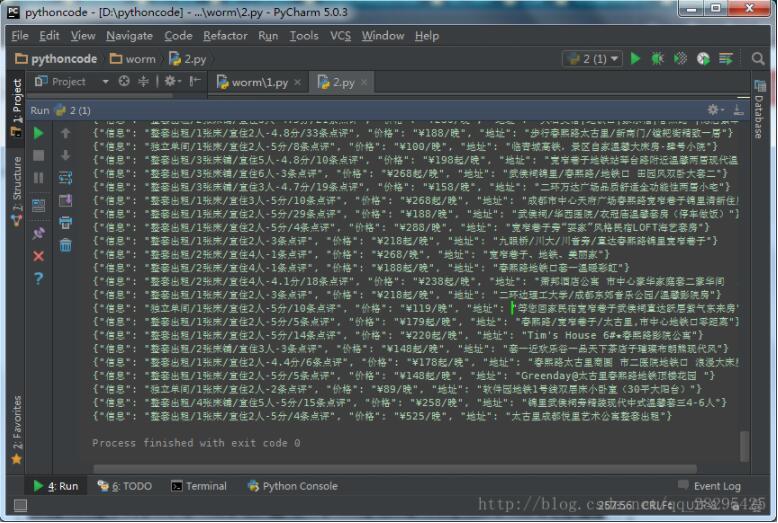
小结:
压注意的是
创建soup
soup = BeautifulSoup(html.content)多个值的for赋值
for dizhi,price,em in zip(dizhis,prices,ems):字典的输出编码问题
json.dumps(data).decode("unicode-escape")如果想获取每个个详细信息可以获取其href属性值
#page_list > ul > li:nth-of-type(1) > a然后获取其属性值get(‘href')获取每个的详情信息在解析页面获取想要的信息加在data字典中
以上这篇Python输出\u编码将其转换成中文的实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持脚本之家。