一直以来都对编译器和解析器有着很大的兴趣,也很清楚一个编译器的概念和整体的框架,但是对于细节部分却不是很了解。我们编写的程序源代码实际上就是一串字符序列,编译器或者解释器可以直接理解并执行这个字符序列,这看起来实在是太奇妙了。本文会用Python实现一个简单的解析器,用于解释一种小的列表操作语言(类似于python的list)。其实编译器、解释器并不神秘,只要对基本的理论理解之后,实现起来也比较简单(当然,一个产品级的编译器或解释器还是很复杂的)。 这种列表语言支持的操作:
veca = [1, 2, 3] # 列表声明
vecb = [4, 5, 6]
print 'veca:', veca # 打印字符串、列表,print expr+
print 'veca * 2:', veca * 2 # 列表与整数乘法
print 'veca + 2:', veca + 2 # 列表与整数加法
print 'veca + vecb:', veca + vecb # 列表加法
print 'veca + [11, 12]:', veca + [11, 12]
print 'veca * vecb:', veca * vecb # 列表乘法
print 'veca:', veca
print 'vecb:', vecb
对应输出:
veca: [1, 2, 3]
veca * 2: [2, 4, 6]
veca + 2: [1, 2, 3, 2]
veca + vecb: [1, 2, 3, 2, 4, 5, 6]
veca + [11, 12]: [1, 2, 3, 2, 11, 12]
veca * vecb: [4, 5, 6, 8, 10, 12, 12, 15, 18, 8, 10, 12]
veca: [1, 2, 3, 2]
vecb: [4, 5, 6]
编译器和解释器在处理输入字符流时,基本上和人理解句子的方式是一致的。比如:
I love you.
如果初学英语,首先需要知道各个单词的意思,然后分析各个单词的词性,符合主-谓-宾的结构,这样才能理解这句话的意思。这句话就是一个字符序列,按照词法划分就得到了一个词法单元流,实际上这就是词法分析,完成从字符流到词法单元流的转化。分析词性,确定主谓宾结构,是按照英语的语法识别出这个结构,这就是语法分析,根据输入的词法单元流识别出语法解析树。最后,再结合单词的意思和语法结构最后得出这句话的意思,这就是语义分析。编译器和解释器处理过程类似,但是要略微复杂一些,这里只关注解释器:
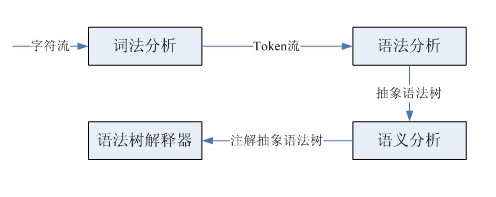
我们只是实现一个很简单的小语言,所以不涉及到语法树的生成,以及后续复杂的语义分析。下面我就来看看词法分析和语法分析。 词法分析和语法分析分别由词法解析器和语法解析器完成。这两种解析器具有类似的结构和功能,它们都是以一个输入序列为输入,然后识别出特定的结构。词法解析器从源代码字符流中解析出一个一个的token(词法单元),而语法解析器识别出子结构和词法单元,然后进行一些处理。可以通过LL(1)递归下降解析器实现这两种解析器,这类解析器完成的步骤是:预测子句的类型,调用解析函数匹配该子结构、匹配词法单元,然后按照需要插入代码,执行自定义操作。 这里对LL(1)做简要介绍,语句的结构通常用树型结构表示,称为解析树,LL(1)做语法解析就依赖于解析树。比如:x = x +2;
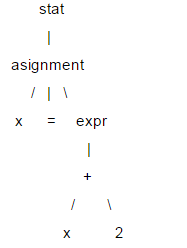 在这棵树中,像x、=和2这样的叶节点,称为终结节点,其他的叫做非终结节点。LL(1)解析时,不需要创建具体的树型数据结构,可以为每个非终结节点编写解析函数,在遇到相应节点时进行调用,这样就可以通过解析函数的调用序列中(相当于树的遍历)获得解析树的信息。在LL(1)解析时,是按照从根节点到叶节点的顺序执行的,所以这是一个“下降”的过程,而解析函数又可以调用自身,所以是“递归”的,因此LL(1)又叫做递归下降解析器。
LL(1)中两个L都是left-to-right的意思,第一个L表示解析器按从左到右的顺序解析输入内容,第二个L表示在下降过程中,也是按照从左到右的顺序遍历子节点,而1表示根据1个向前看单元做预测。
下面看一下列表小语言的实现,首先是语言的文法,文法用于描述一个语言,算是解析器的设计说明书。
在这棵树中,像x、=和2这样的叶节点,称为终结节点,其他的叫做非终结节点。LL(1)解析时,不需要创建具体的树型数据结构,可以为每个非终结节点编写解析函数,在遇到相应节点时进行调用,这样就可以通过解析函数的调用序列中(相当于树的遍历)获得解析树的信息。在LL(1)解析时,是按照从根节点到叶节点的顺序执行的,所以这是一个“下降”的过程,而解析函数又可以调用自身,所以是“递归”的,因此LL(1)又叫做递归下降解析器。
LL(1)中两个L都是left-to-right的意思,第一个L表示解析器按从左到右的顺序解析输入内容,第二个L表示在下降过程中,也是按照从左到右的顺序遍历子节点,而1表示根据1个向前看单元做预测。
下面看一下列表小语言的实现,首先是语言的文法,文法用于描述一个语言,算是解析器的设计说明书。
statlist: stat+
stat: ID '=' expr
| 'print' expr (, expr)*
expr: multipart ('+' multipart)*
| STR
multipart: primary ('*' primary)*
primary: INT
| ID
| '[' expr (',', expr)* ']'
INT: (1..9)(0..9)*
ID: (a..z | A..Z)*
STR: (\".*\") | (\'.*\')
这是用DSL描述的文法,其中大部分概念和正则表达式类似。"a|b"表示a或者b,所有以单引号括起的字符串是关键字,比如:print,=等。大写的单词是词法单元。可以看到这个小语言的文法还是很简单的。有很多解析器生成器可以自动根据文法生成对应的解析器,比如:ANTRL,flex,yacc等,这里采用手写解析器主要是为了理解解析器的原理。下面看一下这个小语言的解释器是如何实现的。 首先是词法解析器,完成字符流到token流的转换。采用LL(1)实现,所以使用1个向前看字符预测匹配的token。对于像INT、ID这样由多个字符组成的词法规则,解析器有一个与之对应的方法。由于语法解析器并不关心空白字符,所以词法解析器在遇到空白字符时直接忽略掉。每个token都有两个属性类型和值,比如整型、标识符类型等,对于整型类型它的值就是该整数。语法解析器需要根据token的类型进行预测,所以词法解析必须返回类型信息。语法解析器以iterator的方式获取token,所以词法解析器实现了next_token方法,以元组方式(type, value)返回下一个token,在没有token的情况时返回EOF。
'''''
A simple lexer of a small vector language.
statlist: stat+
stat: ID '=' expr
| 'print' expr (, expr)*
expr: multipart ('+' multipart)*
| STR
multipart: primary ('*' primary)*
primary: INT
| ID
| '[' expr (',', expr)* ']'
INT: (1..9)(0..9)*
ID: (a..z | A..Z)*
STR: (\".*\") | (\'.*\')
Created on 2012-9-26
@author: bjzllou
'''
EOF = -1
# token type
COMMA = 'COMMA'
EQUAL = 'EQUAL'
LBRACK = 'LBRACK'
RBRACK = 'RBRACK'
TIMES = 'TIMES'
ADD = 'ADD'
PRINT = 'print'
ID = 'ID'
INT = 'INT'
STR = 'STR'
class Veclexer:
'''''
LL(1) lexer.
It uses only one lookahead char to determine which is next token.
For each non-terminal token, it has a rule to handle it.
LL(1) is a quit weak parser, it isn't appropriate for the grammar which is
left-recursive or ambiguity. For example, the rule 'T: T r' is left recursive.
However, it's rather simple and has high performance, and fits simple grammar.
'''
def __init__(self, input):
self.input = input
# current index of the input stream.
self.idx = 1
# lookahead char.
self.cur_c = input[0]
def next_token(self):
while self.cur_c != EOF:
c = self.cur_c
if c.isspace():
self.consume()
elif c == '[':
self.consume()
return (LBRACK, c)
elif c == ']':
self.consume()
return (RBRACK, c)
elif c == ',':
self.consume()
return (COMMA, c)
elif c == '=':
self.consume()
return (EQUAL, c)
elif c == '*':
self.consume()
return (TIMES, c)
elif c == '+':
self.consume()
return (ADD, c)
elif c == '\'' or c == '"':
return self._string()
elif c.isdigit():
return self._int()
elif c.isalpha():
t = self._print()
return t if t else self._id()
else:
raise Exception('not support token')
return (EOF, 'EOF')
def has_next(self):
return self.cur_c != EOF
def _id(self):
n = self.cur_c
self.consume()
while self.cur_c.isalpha():
n += self.cur_c
self.consume()
return (ID, n)
def _int(self):
n = self.cur_c
self.consume()
while self.cur_c.isdigit():
n += self.cur_c
self.consume()
return (INT, int(n))
def _print(self):
n = self.input[self.idx - 1 : self.idx + 4]
if n == 'print':
self.idx += 4
self.cur_c = self.input[self.idx]
return (PRINT, n)
return None
def _string(self):
quotes_type = self.cur_c
self.consume()
s = ''
while self.cur_c != '\n' and self.cur_c != quotes_type:
s += self.cur_c
self.consume()
if self.cur_c != quotes_type:
raise Exception('string quotes is not matched. excepted %s' % quotes_type)
self.consume()
return (STR, s)
def consume(self):
if self.idx >= len(self.input):
self.cur_c = EOF
return
self.cur_c = self.input[self.idx]
self.idx += 1
if __name__ == '__main__':
exp = '''''
veca = [1, 2, 3]
print 'veca:', veca
print 'veca * 2:', veca * 2
print 'veca + 2:', veca + 2
'''
lex = Veclexer(exp)
t = lex.next_token()
while t[0] != EOF:
print t
t = lex.next_token()
运行这个程序,可以得到源代码:
veca = [1, 2, 3]
print 'veca:', veca
print 'veca * 2:', veca * 2
print 'veca + 2:', veca + 2
对应的token序列:
('ID', 'veca')
('EQUAL', '=')
('LBRACK', '[')
('INT', 1)
('COMMA', ',')
('INT', 2)
('COMMA', ',')
('INT', 3)
('RBRACK', ']')
('print', 'print')
('STR', 'veca:')
('COMMA', ',')
('ID', 'veca')
('print', 'print')
('STR', 'veca * 2:')
('COMMA', ',')
('ID', 'veca')
('TIMES', '*')
('INT', 2)
('print', 'print')
('STR', 'veca + 2:')
('COMMA', ',')
('ID', 'veca')
('ADD', '+')
('INT', 2)
接下来看一下语法解析器的实现。语法解析器的的输入是token流,根据一个向前看词法单元预测匹配的规则。对于每个遇到的非终结符调用对应的解析函数,而终结符(token)则match掉,如果不匹配则表示有语法错误。由于都是使用的LL(1),所以和词法解析器类似, 这里不再赘述。
'''''
A simple parser of a small vector language.
statlist: stat+
stat: ID '=' expr
| 'print' expr (, expr)*
expr: multipart ('+' multipart)*
| STR
multipart: primary ('*' primary)*
primary: INT
| ID
| '[' expr (',', expr)* ']'
INT: (1..9)(0..9)*
ID: (a..z | A..Z)*
STR: (\".*\") | (\'.*\')
example:
veca = [1, 2, 3]
vecb = veca + 4 # vecb: [1, 2, 3, 4]
vecc = veca * 3 # vecc:
Created on 2012-9-26
@author: bjzllou
'''
import veclexer
class Vecparser:
'''''
LL(1) parser.
'''
def __init__(self, lexer):
self.lexer = lexer
# lookahead token. Based on the lookahead token to choose the parse option.
self.cur_token = lexer.next_token()
# similar to symbol table, here it's only used to store variables' value
self.symtab = {}
def statlist(self):
while self.lexer.has_next():
self.stat()
def stat(self):
token_type, token_val = self.cur_token
# Asignment
if token_type == veclexer.ID:
self.consume()
# For the terminal token, it only needs to match and consume.
# If it's not matched, it means that is a syntax error.
self.match(veclexer.EQUAL)
# Store the value to symbol table.
self.symtab[token_val] = self.expr()
# print statement
elif token_type == veclexer.PRINT:
self.consume()
v = str(self.expr())
while self.cur_token[0] == veclexer.COMMA:
self.match(veclexer.COMMA)
v += ' ' + str(self.expr())
print v
else:
raise Exception('not support token %s', token_type)
def expr(self):
token_type, token_val = self.cur_token
if token_type == veclexer.STR:
self.consume()
return token_val
else:
v = self.multipart()
while self.cur_token[0] == veclexer.ADD:
self.consume()
v1 = self.multipart()
if type(v1) == int:
v.append(v1)
elif type(v1) == list:
v = v + v1
return v
def multipart(self):
v = self.primary()
while self.cur_token[0] == veclexer.TIMES:
self.consume()
v1 = self.primary()
if type(v1) == int:
v = [x*v1 for x in v]
elif type(v1) == list:
v = [x*y for x in v for y in v1]
return v
def primary(self):
token_type = self.cur_token[0]
token_val = self.cur_token[1]
# int
if token_type == veclexer.INT:
self.consume()
return token_val
# variables reference
elif token_type == veclexer.ID:
self.consume()
if token_val in self.symtab:
return self.symtab[token_val]
else:
raise Exception('undefined variable %s' % token_val)
# parse list
elif token_type == veclexer.LBRACK:
self.match(veclexer.LBRACK)
v = [self.expr()]
while self.cur_token[0] == veclexer.COMMA:
self.match(veclexer.COMMA)
v.append(self.expr())
self.match(veclexer.RBRACK)
return v
def consume(self):
self.cur_token = self.lexer.next_token()
def match(self, token_type):
if self.cur_token[0] == token_type:
self.consume()
return True
raise Exception('expecting %s; found %s' % (token_type, self.cur_token[0]))
if __name__ == '__main__':
prog = '''''
veca = [1, 2, 3]
vecb = [4, 5, 6]
print 'veca:', veca
print 'veca * 2:', veca * 2
print 'veca + 2:', veca + 2
print 'veca + vecb:', veca + vecb
print 'veca + [11, 12]:', veca + [11, 12]
print 'veca * vecb:', veca * vecb
print 'veca:', veca
print 'vecb:', vecb
'''
lex = veclexer.Veclexer(prog)
parser = Vecparser(lex)
parser.statlist()
运行代码便会得到之前介绍中的输出内容。这个解释器极其简陋,只实现了基本的表达式操作,所以不需要构建语法树。如果要为列表语言添加控制结构,就必须实现语法树,在语法树的基础上去解释执行。