问题描述利用搜狗的微信搜索抓取指定公众号的最新一条推送,并保存相应的网页至本地。
问题描述
利用搜狗的微信搜索抓取指定公众号的最新一条推送,并保存相应的网页至本地。
注意点
搜狗微信获取的地址为临时链接,具有时效性。
公众号为动态网页(JavaScript渲染),使用requests.get()获取的内容是不含推送消息的,这里使用selenium+PhantomJS处理
代码
#! /usr/bin/env python3
from selenium import webdriver
from datetime import datetime
import bs4, requests
import os, time, sys
# 获取公众号链接
def getAccountURL(searchURL):
res = requests.get(searchURL)
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text, "lxml")
# 选择第一个链接
account = soup.select('a[uigs="account_name_0"]')
return account[0]['href']
# 获取首篇文章的链接,如果有验证码返回None
def getArticleURL(accountURL):
browser = webdriver.PhantomJS("/Users/chasechoi/Downloads/phantomjs-2.1.1-macosx/bin/phantomjs")
# 进入公众号
browser.get(accountURL)
# 获取网页信息
html = browser.page_source
accountSoup = bs4.BeautifulSoup(html, "lxml")
time.sleep(1)
contents = accountSoup.find_all(hrefs=True)
try:
partitialLink = contents[0]['hrefs']
firstLink = base + partitialLink
except IndexError:
firstLink = None
print('CAPTCHA!')
return firstLink
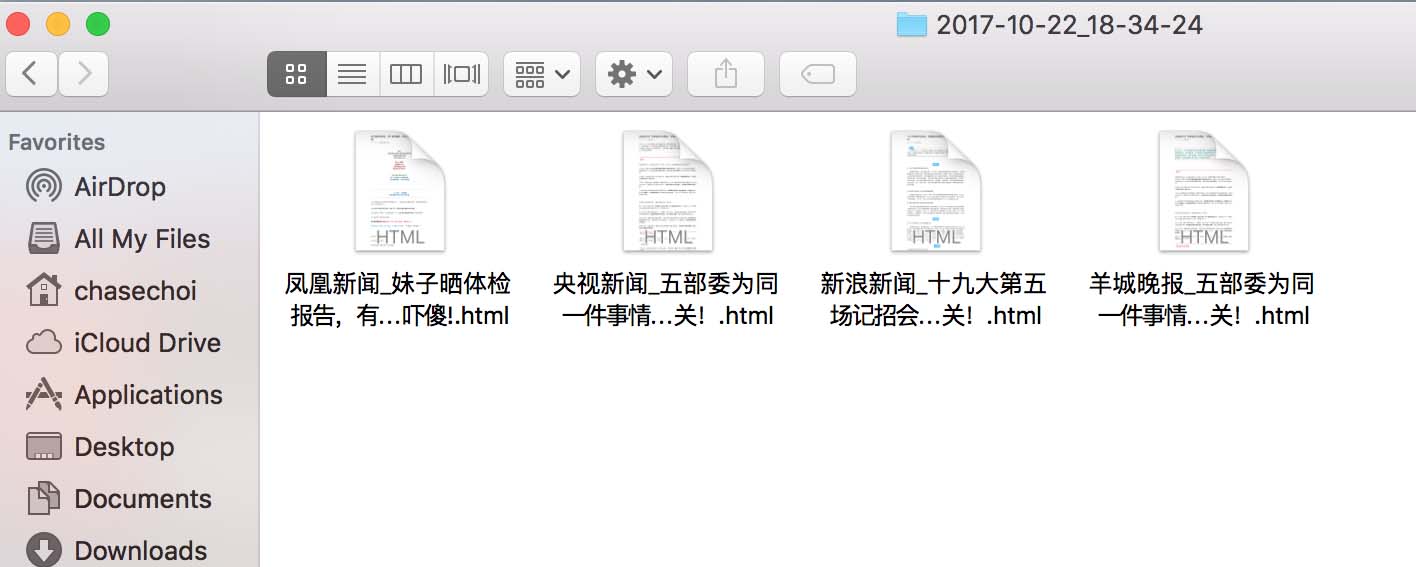
# 创建文件夹存储html网页,以时间命名
def folderCreation():
path = os.path.join(os.getcwd(), datetime.now().strftime('%Y-%m-%d_%H-%M-%S'))
try:
os.makedirs(path)
except OSError as e:
if e.errno != errno.EEXIST:
raise
print("folder not exist!")
return path
# 将html页面写入本地
def writeToFile(path, account, title):
myfile = open("{}/{}_{}.html".format(path, account, title), 'wb')
myfile.write(res.content)
myfile.close()
base ='https://mp.weixin.qq.com'
accountList = ['央视新闻', '新浪新闻','凤凰新闻','羊城晚报']
query = 'http://weixin.sogou.com/weixin?type=1&s_from=input&query='
path = folderCreation()
for index, account in enumerate(accountList):
searchURL = query + account
accountURL = getAccountURL(searchURL)
time.sleep(10)
articleURL = getArticleURL(accountURL)
if articleURL != None:
print("#{}({}/{}): {}".format(account, index+1, len(accountList), accountURL))
# 读取第一篇文章内容
res = requests.get(articleURL)
res.raise_for_status()
detailPage = bs4.BeautifulSoup(res.text, "lxml")
title = detailPage.title.text
print("标题: {}\n链接: {}\n".format(title, articleURL))
writeToFile(path, account, title)
else:
print('{} files successfully written to {}'.format(index, path))
sys.exit()
print('{} files successfully written to {}'.format(len(accountList), path))参考输出
Terminal输出

Finder
分析
链接获取
首先进入搜狗的微信搜索页面,在地址栏中提取需要的部分链接,字符串连接公众号名称,即可生成请求链接
针对静态网页,利用requests获取html文件,再用BeautifulSoup选择需要的内容
针对动态网页,利用selenium+PhantomJS获取html文件,再用BeautifulSoup选择需要的内容
遇到验证码(CAPTCHA),输出提示。此版本代码没有对验证码做实际处理,需要人为访问后,再跑程序,才能避开验证码。
文件写入
使用os.path.join()构造存储路径可以提高通用性。比如Windows路径分隔符使用back slash(\), 而OS X 和 Linux使用forward slash(/),通过该函数能根据平台进行自动转换。
open()使用b(binary mode)参数同样为了提高通用性(适应Windows)
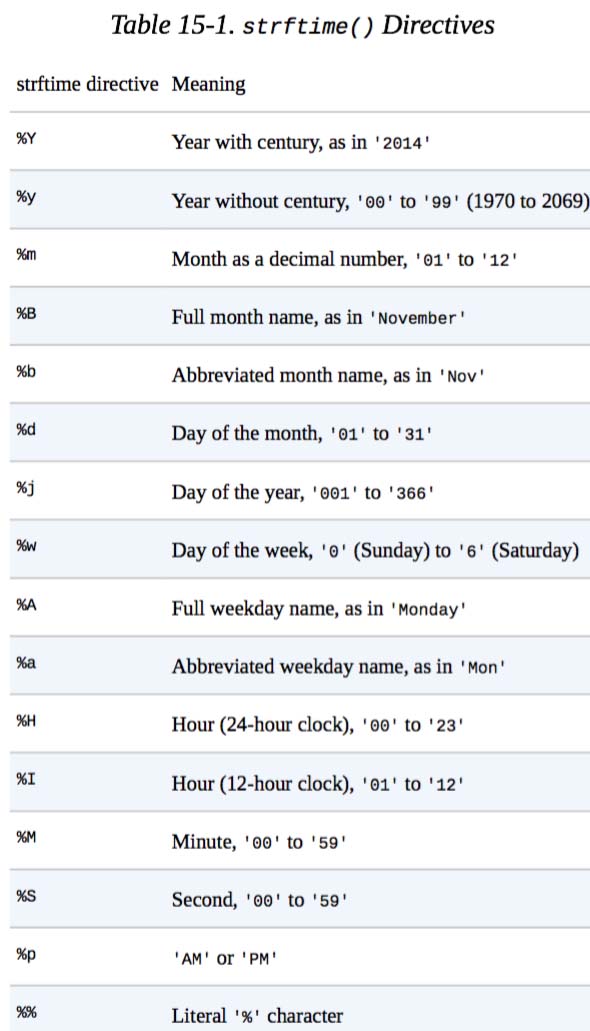
使用datetime.now()获取当前时间进行命名,并通过strftime()格式化时间(函数名中的f代表format),
具体使用参考下表(摘自 Automate the Boring Stuff with Python)
以上这篇python爬虫_微信公众号推送信息爬取的实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持脚本之家。
微信公众号推送信息爬取