由于毕业设计的要求,需要在网站上抓取大量的数据,那么使用Scrapy框架可以让这一过程变得简单不少,毕竟Scrapy是一个为了爬去网站数据、提取结构性数据而编写的应用框架。于是,便开始了我的安装Scrapy框架之旅。可以说这个过程并不是很愉快,各种错误各种出,不过到最后,终于安装上了Scrapy框架。下面总结一下我的Scrapy框架的安装。
1.安装python2.7
由于Scrapy不支持Python3.0,于是我卸载了Python3.0,又重新安装了Python2.7(python2.7安装包),在安装Python2.7的时候,会有一个自动设置环境变量的选项,建议在这里将选项选上,省下后期自己添加环境变量。我们后期自己添加环境变量,就是根据自己实际安装的路径,在系统的环境变量path中添加这两条语句就可以。

在配置完环境之后,我们测试一下我们是否安装配置环境成功。只要在cmd中输入 python –version ,然后能够显示正确的python版本就可以了。如果未能显示,则重启一下cmd试试。

2.安装pywin32
在安装配置好python2.7之后,我们还不能直接安装Scrapy,我们首先需要安装Scrapy依赖的几个工具。接下来安装pywin32(pywin32安装包),这个软件安装的时候一直next就可以了。
3.安装pip
pip实际上一款比较方便的在线软件安装工具,类似于easy install,我们现在安装pip,在之后的软件安装的时候我们就可以使用 pip install 命令了。首先我们要下载get-pip.py(get-pip.py文件) ,下载完成之后,我们在cmd下进行安装,首先切换到文件所在目录,然后输入python get-pip.py语句,便可以进行安装了,但是最头疼的问题出现了,由于该文件会将一些配置文件自动写入到我们的C盘用户文件目录下,而我的用户目录是中文名,就会产生编码异常。
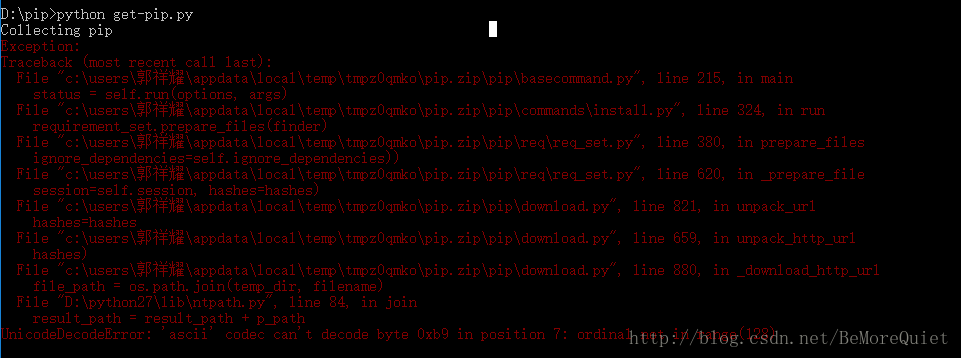
在查找一番资料之后,终于将问题解决了,为了解决中文路径的问题,我们只需要在 D:\python27\Lib\site-packages的目录下新建一个名为 sitecustomize.py的文件即可。

然后在文件内输入以下代码:
import sys
reload(sys)
sys.setdefaultencoding('gbk')当然不一定一定要设置为gbk编码,这个根据自己的电脑的编码来设置。这样我们的中文路径问题就算解决了,我们在重启cmd,在执行安装pip语句之后,pip便顺利完成了。安装完成之后,我们可以进行一下检验,在cmd中输入pip –version,如果显示正确的版本号则说明正确。

4.安装lxml
在安装完成pip之后,本想可以轻松的使用pip install lxml命令来进行安装,但是意外发生了,由于使用pip需要vc2008的环境,而且只能是2008的,2013的都不行。没办法为了使用这款工具,只能在去求教度娘,终于找到了解决办法,原来微软给我们提供了VcForPython(VCForPython安装包),这样我们就不用安装VC2008了,这样之后,我们便可以使用 pip install lxml进行安装了。
5.安装pyOpenSSL
在安装这个工具的时候我们便可以使用 pip install pyOpenSSL 语句来进行安装了,安装的速度取决于网速了。
6.安装Scrapy
终于经历一波坎坷之后,我们终于可以安装Scrapy框架了,在cmd中输入 pip install Scrapy命令之后,我们就可以等着享受成功的喜悦了。在安装完成之后,我们在cmd中输入Scrapy来检测一下,是否真正的安装成功。

终于安装好了,还是有点成就感的。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。