大家可以在Github上clone全部源码。
Github:https://github.com/williamzxl/Scrapy_CrawlMeiziTu
Scrapy官方文档:http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html
基本上按照文档的流程走一遍就基本会用了。
Step1:
在开始爬取之前,必须创建一个新的Scrapy项目。 进入打算存储代码的目录中,运行下列命令:
scrapy startproject CrawlMeiziTu该命令将会创建包含下列内容的 tutorial 目录:
CrawlMeiziTu/
scrapy.cfg
CrawlMeiziTu/
__init__.py
items.py
pipelines.py
settings.py
middlewares.py
spiders/
__init__.py
...
cd CrawlMeiziTu
scrapy genspider Meizitu http://www.meizitu.com/a/list_1_1.html该命令将会创建包含下列内容的 tutorial 目录:
CrawlMeiziTu/
scrapy.cfg
CrawlMeiziTu/
__init__.py
items.py
pipelines.py
settings.py
middlewares.py
spiders/
Meizitu.py
__init__.py
...我们主要编辑的就如下图箭头所示:
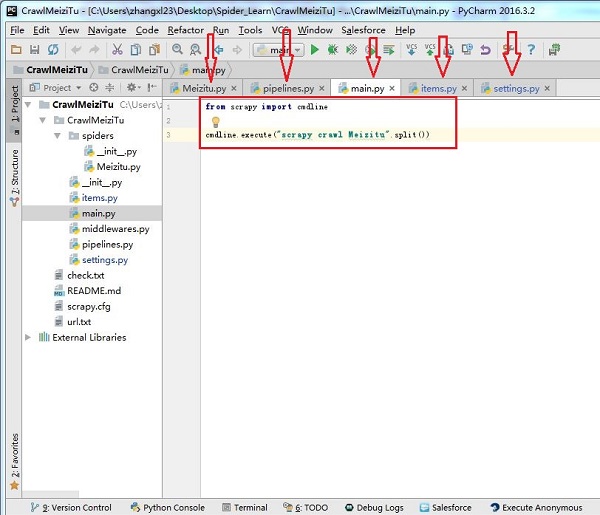
main.py是后来加上的,加了两条命令,
from scrapy import cmdline
cmdline.execute("scrapy crawl Meizitu".split())主要为了方便运行。
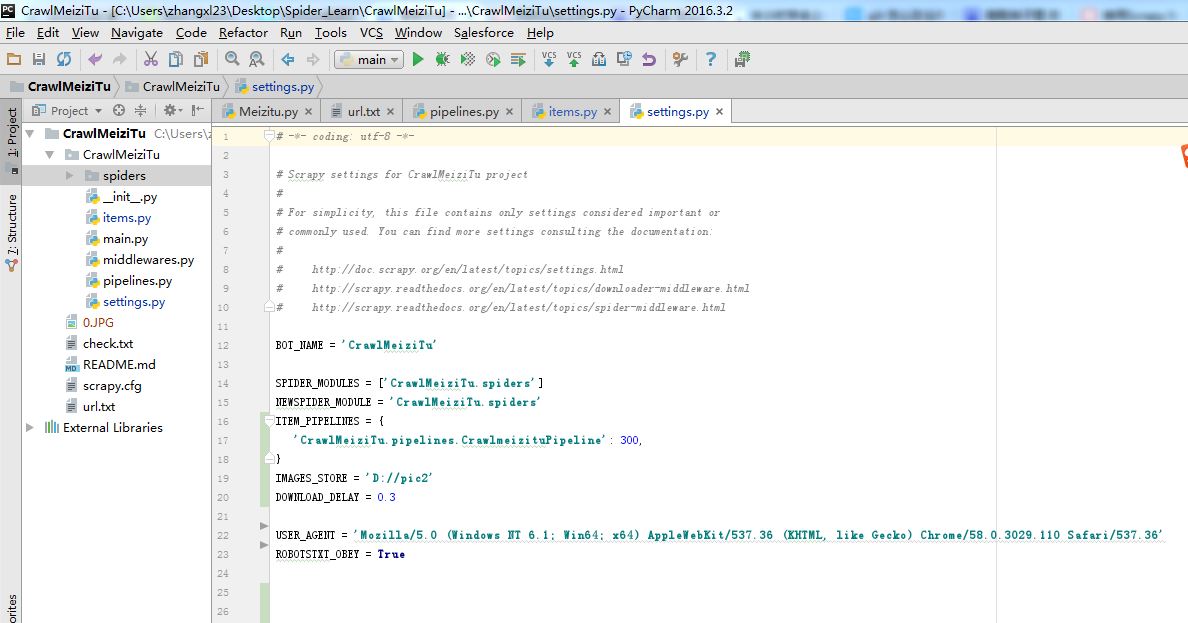
Step2:编辑Settings,如下图所示
BOT_NAME = 'CrawlMeiziTu'
SPIDER_MODULES = ['CrawlMeiziTu.spiders']
NEWSPIDER_MODULE = 'CrawlMeiziTu.spiders'
ITEM_PIPELINES = {
'CrawlMeiziTu.pipelines.CrawlmeizituPipeline': 300,
}
IMAGES_STORE = 'D://pic2'
DOWNLOAD_DELAY = 0.3
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
ROBOTSTXT_OBEY = True主要设置USER_AGENT,下载路径,下载延迟时间
Step3:编辑Items.
Items主要用来存取通过Spider程序抓取的信息。由于我们爬取妹子图,所以要抓取每张图片的名字,图片的连接,标签等等
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class CrawlmeizituItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
#title为文件夹名字
title = scrapy.Field()
url = scrapy.Field()
tags = scrapy.Field()
#图片的连接
src = scrapy.Field()
#alt为图片名字
alt = scrapy.Field()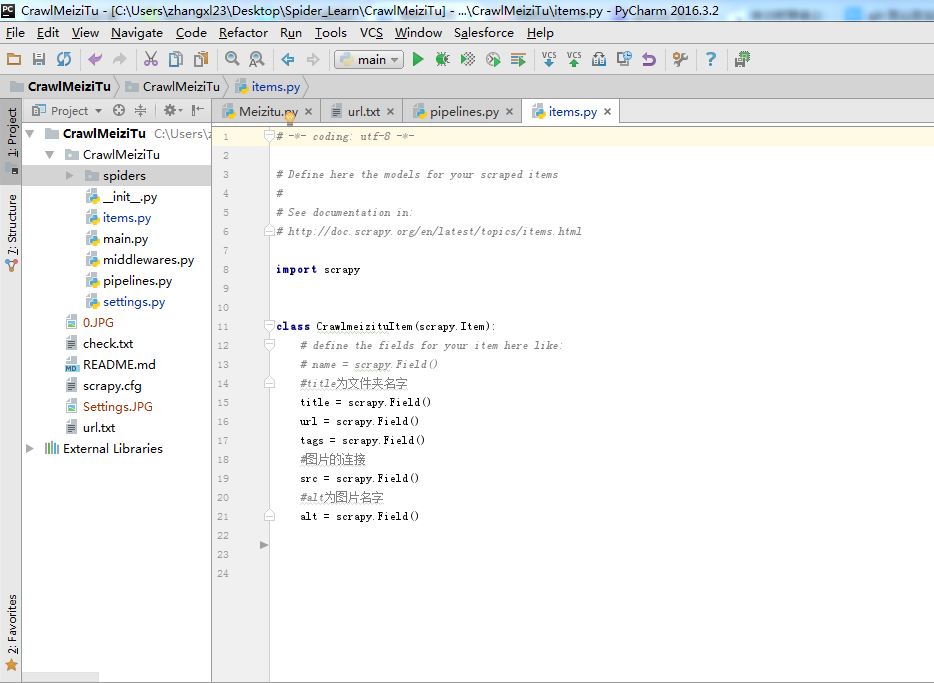
Step4:编辑Pipelines
Pipelines主要对items里面获取的信息进行处理。比如说根据title创建文件夹或者图片的名字,根据图片链接下载图片。
# -*- coding: utf-8 -*-
import os
import requests
from CrawlMeiziTu.settings import IMAGES_STORE
class CrawlmeizituPipeline(object):
def process_item(self, item, spider):
fold_name = "".join(item['title'])
header = {
'USER-Agent': 'User-Agent:Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36',
'Cookie': 'b963ef2d97e050aaf90fd5fab8e78633',
#需要查看图片的cookie信息,否则下载的图片无法查看
}
images = []
# 所有图片放在一个文件夹下
dir_path = '{}'.format(IMAGES_STORE)
if not os.path.exists(dir_path) and len(item['src']) != 0:
os.mkdir(dir_path)
if len(item['src']) == 0:
with open('..//check.txt', 'a+') as fp:
fp.write("".join(item['title']) + ":" + "".join(item['url']))
fp.write("\n")
for jpg_url, name, num in zip(item['src'], item['alt'],range(0,100)):
file_name = name + str(num)
file_path = '{}//{}'.format(dir_path, file_name)
images.append(file_path)
if os.path.exists(file_path) or os.path.exists(file_name):
continue
with open('{}//{}.jpg'.format(dir_path, file_name), 'wb') as f:
req = requests.get(jpg_url, headers=header)
f.write(req.content)
return item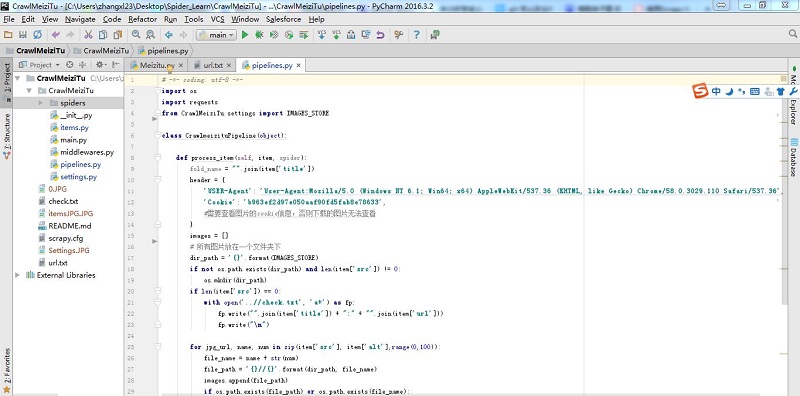
Step5:编辑Meizitu的主程序。
最重要的主程序:
# -*- coding: utf-8 -*-
import scrapy
from CrawlMeiziTu.items import CrawlmeizituItem
#from CrawlMeiziTu.items import CrawlmeizituItemPage
import time
class MeizituSpider(scrapy.Spider):
name = "Meizitu"
#allowed_domains = ["meizitu.com/"]
start_urls = []
last_url = []
with open('..//url.txt', 'r') as fp:
crawl_urls = fp.readlines()
for start_url in crawl_urls:
last_url.append(start_url.strip('\n'))
start_urls.append("".join(last_url[-1]))
def parse(self, response):
selector = scrapy.Selector(response)
#item = CrawlmeizituItemPage()
next_pages = selector.xpath('//*[@id="wp_page_numbers"]/ul/li/a/@href').extract()
next_pages_text = selector.xpath('//*[@id="wp_page_numbers"]/ul/li/a/text()').extract()
all_urls = []
if '下一页' in next_pages_text:
next_url = "http://www.meizitu.com/a/{}".format(next_pages[-2])
with open('..//url.txt', 'a+') as fp:
fp.write('\n')
fp.write(next_url)
fp.write("\n")
request = scrapy.http.Request(next_url, callback=self.parse)
time.sleep(2)
yield request
all_info = selector.xpath('//h3[@class="tit"]/a')
#读取每个图片夹的连接
for info in all_info:
links = info.xpath('//h3[@class="tit"]/a/@href').extract()
for link in links:
request = scrapy.http.Request(link, callback=self.parse_item)
time.sleep(1)
yield request
# next_link = selector.xpath('//*[@id="wp_page_numbers"]/ul/li/a/@href').extract()
# next_link_text = selector.xpath('//*[@id="wp_page_numbers"]/ul/li/a/text()').extract()
# if '下一页' in next_link_text:
# nextPage = "http://www.meizitu.com/a/{}".format(next_link[-2])
# item['page_url'] = nextPage
# yield item
#抓取每个文件夹的信息
def parse_item(self, response):
item = CrawlmeizituItem()
selector = scrapy.Selector(response)
image_title = selector.xpath('//h2/a/text()').extract()
image_url = selector.xpath('//h2/a/@href').extract()
image_tags = selector.xpath('//div[@class="metaRight"]/p/text()').extract()
if selector.xpath('//*[@id="picture"]/p/img/@src').extract():
image_src = selector.xpath('//*[@id="picture"]/p/img/@src').extract()
else:
image_src = selector.xpath('//*[@id="maincontent"]/div/p/img/@src').extract()
if selector.xpath('//*[@id="picture"]/p/img/@alt').extract():
pic_name = selector.xpath('//*[@id="picture"]/p/img/@alt').extract()
else:
pic_name = selector.xpath('//*[@id="maincontent"]/div/p/img/@alt').extract()
#//*[@id="maincontent"]/div/p/img/@alt
item['title'] = image_title
item['url'] = image_url
item['tags'] = image_tags
item['src'] = image_src
item['alt'] = pic_name
print(item)
time.sleep(1)
yield item
总结
以上所述是小编给大家介绍的Python使用Scrapy爬虫框架全站爬取图片并保存本地的实现代码,希望对大家有所帮助,如果大家啊有任何疑问欢迎给我留言,小编会及时回复大家的!