本文主要是用PyTorch来实现一个简单的回归任务。
编辑器:spyder
1.引入相应的包及生成伪数据
import torch
import torch.nn.functional as F # 主要实现激活函数
import matplotlib.pyplot as plt # 绘图的工具
from torch.autograd import Variable
# 生成伪数据
x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim = 1)
y = x.pow(2) + 0.2 * torch.rand(x.size())
# 变为Variable
x, y = Variable(x), Variable(y)
其中torch.linspace是为了生成连续间断的数据,第一个参数表示起点,第二个参数表示终点,第三个参数表示将这个区间分成平均几份,即生成几个数据。因为torch只能处理二维的数据,所以我们用torch.unsqueeze给伪数据添加一个维度,dim表示添加在第几维。torch.rand返回的是[0,1)之间的均匀分布。
2.绘制数据图像
在上述代码后面加下面的代码,然后运行可得伪数据的图形化表示:
# 绘制数据图像
plt.scatter(x.data.numpy(), y.data.numpy())
plt.show()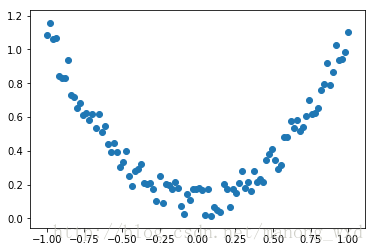
3.建立神经网络
class Net(torch.nn.Module):
def __init__(self, n_feature, n_hidden, n_output):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(n_feature, n_hidden) # hidden layer
self.predict = torch.nn.Linear(n_hidden, n_output) # output layer
def forward(self, x):
x = F.relu(self.hidden(x)) # activation function for hidden layer
x = self.predict(x) # linear output
return x
net = Net(n_feature=1, n_hidden=10, n_output=1) # define the network
print(net) # net architecture
一般神经网络的类都继承自torch.nn.Module,__init__()和forward()两个函数是自定义类的主要函数。在__init__()中都要添加一句super(Net, self).__init__(),这是固定的标准写法,用于继承父类的初始化函数。__init__()中只是对神经网络的模块进行了声明,真正的搭建是在forwad()中实现。自定义类中的成员都通过self指针来进行访问,所以参数列表中都包含了self。
如果想查看网络结构,可以用print()函数直接打印网络。本文的网络结构输出如下:
Net (
(hidden): Linear (1 -> 10)
(predict): Linear (10 -> 1)
)
4.训练网络
# 训练100次
for t in range(100):
prediction = net(x) # input x and predict based on x
loss = loss_func(prediction, y) # 一定要是输出在前,标签在后 (1. nn output, 2. target)
optimizer.zero_grad() # clear gradients for next train
loss.backward() # backpropagation, compute gradients
optimizer.step() # apply gradients
训练网络之前我们需要先定义优化器和损失函数。torch.optim包中包括了各种优化器,这里我们选用最常见的SGD作为优化器。因为我们要对网络的参数进行优化,所以我们要把网络的参数net.parameters()传入优化器中,并设置学习率(一般小于1)。
由于这里是回归任务,我们选择torch.nn.MSELoss()作为损失函数。
由于优化器是基于梯度来优化参数的,并且梯度会保存在其中。所以在每次优化前要通过optimizer.zero_grad()把梯度置零,然后再后向传播及更新。
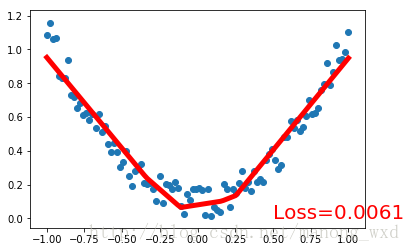
5.可视化训练过程
plt.ion() # something about plotting
for t in range(100):
...
if t % 5 == 0:
# plot and show learning process
plt.cla()
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
plt.text(0.5, 0, 'Loss=%.4f' % loss.data[0], fontdict={'size': 20, 'color': 'red'})
plt.pause(0.1)
plt.ioff()
plt.show()
6.运行结果
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。