相关分析(correlationanalysis)研究两个或两个以上随机变量之间相互依存关系的方向和密切
相关分析(correlation analysis)
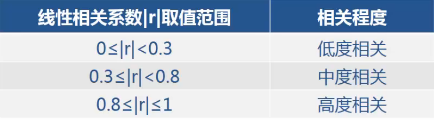
研究两个或两个以上随机变量之间相互依存关系的方向和密切程度的方法。 线性相关关系主要采用皮尔逊(Pearson)相关系数r来度量连续变量之间线性相关强度; r>0,线性正相关;r<0,线性负相关; r=0,两个变量之间不存在线性关系,并不代表两个变量之间不存在任何关系。
相关分析函数 DataFrame.corr() Series.corr(other)
函数说明: 如果由数据框调用corr函数,那么将会计算每个列两两之间的相似度 如果由序列调用corr方法,那么只是该序列与传入的序列之间的相关度
返回值: DataFrame调用;返回DataFrame
Series调用:返回一个数值型,大小为相关度
import numpy
import pandas
data = pandas.read_csv(
'C:/Users/ZL/Desktop/Python/5.4/data.csv'
)
bins = [
min(data.年龄)-1, 20, 30, 40, max(data.年龄)+1
]
labels = [
'20岁以及以下', '21岁到30岁', '31岁到40岁', '41岁以上'
]
data['年龄分层'] = pandas.cut(
data.年龄,
bins,
labels=labels
)
ptResult = data.pivot_table(
values=['年龄'],
index=['年龄分层'],
columns=['性别'],
aggfunc=[numpy.size]
File "<ipython-input-1-ae921a24967f>", line 25
aggfunc=[numpy.size]
^
SyntaxError: unexpected EOF while parsing
import numpy
import pandas
data = pandas.read_csv(
'C:/Users/ZL/Desktop/Python/5.4/data.csv'
)
bins = [
min(data.年龄)-1, 20, 30, 40, max(data.年龄)+1
]
labels = [
'20岁以及以下', '21岁到30岁', '31岁到40岁', '41岁以上'
]
data['年龄分层'] = pandas.cut(
data.年龄,
bins,
labels=labels
)
ptResult = data.pivot_table(
values=['年龄'],
index=['年龄分层'],
columns=['性别'],
aggfunc=[numpy.size]
)
ptResult
Out[4]:
size
年龄
性别 女 男
年龄分层
20岁以及以下 111 1950
21岁到30岁 2903 43955
31岁到40岁 735 7994
41岁以上 567 886以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
Python 相关分析 Python correlation analysis