双向RNN:bidirectional_dynamic_rnn()函数的使用详解
先说下为什么要使用到双向RNN,在读一篇文章的时候,上文提到的信息十分的重要,但这些信息是不足以捕捉文章信息的,下文隐含的信息同样会对该时刻的语义产生影响。
举一个不太恰当的例子,某次工作会议上,领导进行“简洁地”总结,他会在第一句告诉你:“下面,为了节约时间,我简单地说两点…”,(…此处略去五百字…),“首先,….”,(…此处略去一万字…),“碍于时间的关系,我要加快速度了,下面我简要说下第二点…”(…此处再次略去五千字…)“好的,我想说的大概就是这些”(…此处又略去了二百字…),“谢谢大家!”如果将这篇发言交给一个单层的RNN网络去学习,因为“首先”和“第二点”中间隔得实在太久,等到开始学习“第二点”时,网络已经忘记了“简单地说两点”这个重要的信息,最终的结果就只剩下在风中凌乱了。。。于是我们决定加一个反向的网络,从后开始往前听,对于这层网络,他首先听到的就是“第二点”,然后是“首先”,最后,他对比了一下果然仅仅是“简要地两点”,在于前向的网络进行结合,就深入学习了领导的指导精神。
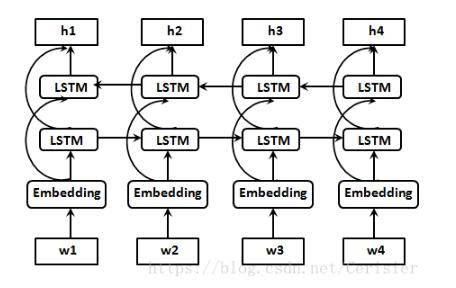
上图是一个双向LSTM的结构图,对于最后输出的每个隐藏状态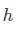 都是前向网络和后向网络的元组,即
都是前向网络和后向网络的元组,即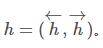 其中每一个
其中每一个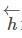 或者
或者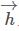 又是一个由隐藏状态和细胞状态组成的元组(或者是concat)。同样最终的output也是需要将前向和后向的输出concat起来的,这样就保证了在最终时刻,无论是输出还是隐藏状态都是有考虑了上文和下文信息的。
又是一个由隐藏状态和细胞状态组成的元组(或者是concat)。同样最终的output也是需要将前向和后向的输出concat起来的,这样就保证了在最终时刻,无论是输出还是隐藏状态都是有考虑了上文和下文信息的。
下面就来看下tensorflow中已经集成的 tf.nn.bidirectional_dynamic_rnn() 函数。似乎双向的暂时只有这一个动态的RNN方法,不过想想也能理解,这种结构暂时也只会在encoder端出现,无论你的输入是pad到了定长或者是不定长的,动态RNN都是可以处理的。
具体的定义如下:
tf.nn.bidirectional_dynamic_rnn(
cell_fw,
cell_bw,
inputs,
sequence_length=None,
initial_state_fw=None,
initial_state_bw=None,
dtype=None,
parallel_iterations=None,
swap_memory=False,
time_major=False,
scope=None
)仔细看这个方法似乎和dynamic_rnn()没有太大区别,无非是多加了一个bw的部分,事实上也的确如此。先看下前向传播的部分:
with vs.variable_scope(scope or "bidirectional_rnn"):
# Forward direction
with vs.variable_scope("fw") as fw_scope:
output_fw, output_state_fw = dynamic_rnn(
cell=cell_fw, inputs=inputs,
sequence_length=sequence_length,
initial_state=initial_state_fw,
dtype=dtype,
parallel_iterations=parallel_iterations,
swap_memory=swap_memory,
scope=fw_scope)完全就是一个dynamic_rnn(),至于你选择LSTM或者GRU,只是cell的定义不同罢了。而双向RNN的核心就在于反向的bw部分。刚才说过,反向部分就是从后往前读,而这个翻转的部分,就要用到一个reverse_sequence()的方法,来看一下这一部分:
with vs.variable_scope("bw") as bw_scope:
# ———————————— 此处是重点 ————————————
inputs_reverse = _reverse(
inputs, seq_lengths=sequence_length,
seq_dim=time_dim, batch_dim=batch_dim)
# ————————————————————————————————————
tmp, output_state_bw = dynamic_rnn(
cell=cell_bw,
inputs=inputs_reverse,
sequence_length=sequence_length,
initial_state=initial_state_bw,
dtype=dtype,
parallel_iterations=parallel_iterations,
swap_memory=swap_memory,
time_major=time_major,
scope=bw_scope)我们可以看到,这里的输入不再是inputs,而是一个inputs_reverse,根据time_major的取值,time_dim和batch_dim组合的 {0,1} 取值正好相反,也就对应了时间维和批量维的词序关系。
而最终的输出:
outputs = (output_fw, output_bw)
output_states = (output_state_fw, output_state_bw)这里还有最后的一个小问题,output_states是一个元组的元组,我个人的处理方法是用c_fw,h_fw = output_state_fw和c_bw,h_bw = output_state_bw,最后再分别将c和h状态concat起来,用tf.contrib.rnn.LSTMStateTuple()函数生成decoder端的初始状态。
以上这篇双向RNN:bidirectional_dynamic_rnn()函数的使用详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持脚本之家。