一开始的目的是学习十大挖掘算法(机器学习算法),并用编码实现一遍,但越往后学习,越往后实现编码,越发现自己的编码水平低下,学习能力低。这一个k-means算法用Python实现竟用了三天时间,可见编码水平之低,而且在编码的过程中看了别人的编码,才发现自己对numpy认识和运用的不足,在自己的代码中有很多可以优化的地方,比如求均值的地方可以用mean直接对数组求均值,再比如去最小值的下标,我用的是argsort排序再取列表第一个,但是有argmin可以直接用啊。下面的代码中这些可以优化的并没有改,这么做的原因是希望做到抛砖引玉,欢迎大家丢玉,如果能给出优化方法就更好了
一.k-means算法
人以类聚,物以群分,k-means聚类算法就是体现。数学公式不要,直接用白话描述的步骤就是:
1.随机选取k个质心(k值取决于你想聚成几类) 2.计算样本到质心的距离,距离质心距离近的归为一类,分为k类 3.求出分类后的每类的新质心 4.判断新旧质心是否相同,如果相同就代表已经聚类成功,如果没有就循环2-3直到相同
用程序的语言描述就是:
1.输入样本 2.随机去k个质心 3.重复下面过程知道算法收敛:
计算样本到质心距离(欧几里得距离) 样本距离哪个质心近,就记为那一类 计算每个类别的新质心(平均值)
二.需求分析
数据来源:从国际统计局down的数据,数据为城乡居民家庭人均收入及恩格尔系数(点击这里下载)
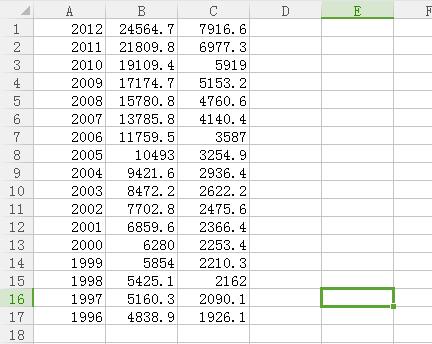
数据描述:
1.横轴:城镇居民家庭人均可支配收入和农村居民家庭人均纯收入, 2.纵轴:1996-2012年。 3.数据为年度数据
需求说明:我想把这数据做个聚类分析,看人民的收入大概经历几个阶段(感觉我好高大上啊)
需求分析:
1.由于样本数据有限,就两列,用k-means聚类有很大的准确性 2.用文本的形式导入数据,结果输出聚类后的质心,这样就能看出人民的收入经历了哪几个阶段
三.Python实现
引入numpy模块,借用其中的一些方法进行数据处理,上代码:
# -*- coding=utf-8 -*-
"""
authon:xuwf
created:2017-02-07
purpose:实现k-means算法
"""
import numpy as np
import random
'''装载数据'''
def load():
data=np.loadtxt('data\k-means.csv',delimiter=',')
return data
'''计算距离'''
def calcDis(data,clu,k):
clalist=[] #存放计算距离后的list
data=data.tolist() #转化为列表
clu=clu.tolist()
for i in range(len(data)):
clalist.append([])
for j in range(k):
dist=round(((data[i][1]-clu[j][0])**2+(data[i][2]-clu[j][1])**2)*0.05,1)
clalist[i].append(dist)
clalist=np.array(clalist) #转化为数组
return clalist
'''分组'''
def group(data,clalist,k):
grouplist=[] #存放分组后的集群
claList=clalist.tolist()
data=data.tolist()
for i in range(k):
#确定要分组的个数,以空列表的形式,方便下面进行数据的插入
grouplist.append([])
for j in range(len(clalist)):
sortNum=np.argsort(clalist[j])
grouplist[sortNum[0]].append(data[j][1:])
grouplist=np.array(grouplist)
return grouplist
'''计算质心'''
def calcCen(data,grouplist,k):
clunew=[]
data=data.tolist()
grouplist=grouplist.tolist()
templist=[]
#templist=np.array(templist)
for i in range(k):
#计算每个组的新质心
sumx=0
sumy=0
for j in range(len(grouplist[i])):
sumx+=grouplist[i][j][0]
sumy+=grouplist[i][j][1]
clunew.append([round(sumx/len(grouplist[i]),1),round(sumy/len(grouplist[i]),1)])
clunew=np.array(clunew)
#clunew=np.mean(grouplist,axis=1)
return clunew
'''优化质心'''
def classify(data,clu,k):
clalist=calcDis(data,clu,k) #计算样本到质心的距离
grouplist=group(data,clalist,k) #分组
for i in range(k):
#替换空值
if grouplist[i]==[]:
grouplist[i]=[4838.9,1926.1]
clunew=calcCen(data,grouplist,k)
sse=clunew-clu
#print "the clu is :%r\nthe group is :%r\nthe clunew is :%r\nthe sse is :%r" %(clu,grouplist,clunew,sse)
return sse,clunew,data,k
if __name__=='__main__':
k=3 #给出要分类的个数的k值
data=load() #装载数据
clu=random.sample(data[:,1:].tolist(),k) #随机取质心
clu=np.array(clu)
sse,clunew,data,k=classify(data,clu,k)
while np.any(sse!=0):
sse,clunew,data,k=classify(data,clunew,k)
clunew=np.sort(clunew,axis=0)
print "the best cluster is %r" %clunew
四.测试
直接运行程序就可以,k值可以自己设置,会发现k=3的时候结果数据是最稳定的,这里我就不贴图了 需要注意的是上面的代码里面主函数里的数据结构都是array,但是在每个小函数里就有可能转化成了list,主要原因是需要进行array的一下方法进行计算,而转化为list的原因是需要向数组中插入数据,但是array做不到啊(至少我没找到怎么做)。于是这里就出现了一个问题,那就是数据结构混乱,到最后我调试了半天,干脆将主函数的数据结构都转化成array,在小函数中输入的array,输出的时候也转化成了array,这样就清晰多了
五.算法分析
单看这个算法还是较好理解的,但是算法的目的是聚类,那就要考虑到聚类的准确性,这里聚类的准确性取决于k值、初始质心和距离的计算方式。
- k值就要看个人经验和多次试验了,算法结果在哪个k值的时候更稳定就证明这个分类更加具有可信度,其中算法结果的稳定也取决于初始质心的选择
- 初始质心一般都是随机选取的,怎么更准确的选择初始质心呢?有种较难实现的方法是将样本中所有点组合起来都取一遍,然后计算算法收敛后的所有质心到样本的距离之和,哪个距离最小,哪个的聚类就最为成功,相对应的初始质心就选取的最为准确。但是这种方法有很大的计算量,如果样本很大,维度很多,那就是让电脑干到死的节奏
- 距离的计算方式取决于样本的特征,有很多的选择,入欧式距离,夹角余弦距离,曼哈顿距离等,具体的数据特性用具体的距离计算方式
六.项目评测
1.项目总结数据源的数据很干净,不需要进行过多的数据清洗和数据降噪,数据预处理的工作成本接近为0。需求基本实现 2.还能做什么:可以用计算最小距离之和的方法求出最佳k值,这样就可以得到稳定的收入阶梯;可以引入画图模块,将数据结果进行数据可视化,显得更加直观;如果可能应该引入更多的维度或更多的数据,这样得到的聚类才更有说服力。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。