同样的,只会讲解跟SQLSERVER不同的地方
插入
将多行查询结果插入到表中
语法
INSERT INTO table_name1(column_list1) SELECT (column_list2) FROM table_name2 WHERE (condition)
INSERT INTO SELECT 在SQLSERVER里也是支持的
table_name1指定待插入数据的表;column_list1指定待插入表中要插入数据的哪些列;table_name2指定插入数据是从
哪个表中查询出来的;column_list2指定数据来源表的查询列,该列表必须和column_list1列表中的字段个数相同,数据类型相同;
condition指定SELECT语句的查询条件
从person_old表中查询所有的记录,并将其插入到person表
CREATE TABLE person (
id INT UNSIGNED NOT NULL AUTO_INCREMENT,
NAME CHAR(40) NOT NULL DEFAULT '',
age INT NOT NULL DEFAULT 0,
info CHAR(50) NULL,
PRIMARY KEY (id)
)
CREATE TABLE person_old (
id INT UNSIGNED NOT NULL AUTO_INCREMENT,
NAME CHAR(40) NOT NULL DEFAULT '',
age INT NOT NULL DEFAULT 0,
info CHAR(50) NULL,
PRIMARY KEY (id)
)
INSERT INTO person_old
VALUES (11,'Harry',20,'student'),(12,'Beckham',31,'police')
SELECT * FROM person_old

可以看到,插入记录成功,person_old表现在有两条记录。接下来将person_oldperson_old表中的所有记录插入到person表
INSERT INTO person(id,NAME,age,info)
SELECT id,NAME,age,info FROM person_old;
SELECT * FROM person

可以看到数据转移成功,这里的id字段为自增的主键,在插入时要保证该字段值的唯一性,如果不能确定,可以插入的时候忽略该字段,
只插入其他字段的值
如果再执行一次就会出错

MYSQL和SQLSERVER的区别:
区别一
当要导入的数据中有重复值的时候,MYSQL会有三种方案
方案一:使用 ignore 关键字
方案二:使用 replace into
方案三:ON DUPLICATE KEY UPDATE
第二和第三种方案这里不作介绍,因为比较复杂,而且不符合要求,这里只讲第一种方案
TRUNCATE TABLE person
TRUNCATE TABLE persona_old
INSERT INTO person_old
VALUES (11,'Harry',20,'student'),(12,'Beckham',31,'police')
##注意下面这条insert语句是没有ignore关键字的
INSERT INTO person(id,NAME,age,info)
SELECT id,NAME,age,info FROM person_old;
INSERT INTO person_old
VALUES (13,'kay',26,'student')
##注意下面这条insert语句是有ignore关键字的
INSERT IGNORE INTO person(id,NAME,age,info)
SELECT id,NAME,age,info FROM person_old;


可以看到插入成功
SQLSERVER
在SQLSERVER这边,如果要忽略重复键,需要在建表的时候指定 WITH (IGNORE_DUP_KEY = ON) ON [PRIMARY]
这样在插入重复值的时候,SQLSERVER第一次会保留值,第二次发现有重复值的时候,SQLSERVER就会忽略掉
区别二
插入自增列时的区别
SQLSERVER需要使用 SET IDENTITY_INSERT 表名 ON 才能把自增字段的值插入到表中,如果不加 SET IDENTITY_INSERT 表名 ON
则在插入数据到表中时,不能指定自增字段的值,则id字段不能指定值,SQLSERVER会自动帮你自动增加一
INSERTINTO person(NAME,age,info) VALUES ('feicy',33,'student')
而MYSQL则不需要,而且自由度非常大
你可以将id字段的值指定为NULL,MYSQL会自动帮你增一
INSERTINTO person(id,NAME,age,info) VALUES (NULL,'feicy',33,'student')

也可以指定值
INSERT IGNORE INTO person(id,NAME,age,info) VALUES (16,'tom',88,'student')

也可以不写id的值,MYSQL会自动帮你增一
INSERT IGNORE INTO person(NAME,age,info) VALUES ('amy',12,'bb')
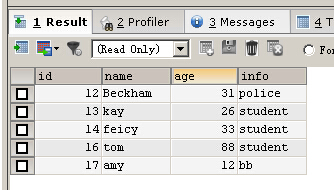
你可以指定id字段的值也可以不指定,指定的时候只要当前id字段列没有你正在插入的那个值就可以,即没有重复值就可以
自由度非常大,而且无须指定 SET IDENTITY_INSERT 表名 ON 选项
区别三
唯一索引的NULL值重复问题
MYSQL
在MYSQL中UNIQUE 索引将会对null字段失效
insert into test(a) values(null)
insert into test(a) values(null)
上面的插入语句是可以重复插入的(联合唯一索引也一样)
SQLSERVER
SQLSERVER则不行
CREATE TABLE person (
id INT NOT NULL IDENTITY(1,1),
NAME CHAR(40) NULL DEFAULT '',
age INT NOT NULL DEFAULT 0,
info CHAR(50) NULL,
PRIMARY KEY (id)
)
CREATE UNIQUE INDEX IX_person_unique ON [dbo].[person](name)
INSERT INTO [dbo].[person]
( [NAME], [age], [info] )
VALUES ( NULL, -- NAME - char(40)
1, -- age - int
'aa' -- info - char(50)
),
( NULL, -- NAME - char(40)
2, -- age - int
'bb' -- info - char(50)
)
消息 2601,级别 14,状态 1,第 1 行
不能在具有唯一索引“IX_person_unique”的对象“dbo.person”中插入重复键的行。重复键值为 (<NULL>)。
语句已终止。
更新
更新比较简单,就不多说了
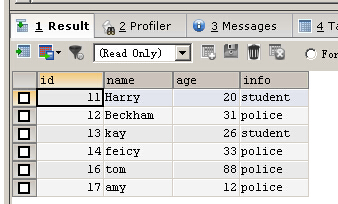
UPDATE person SET info ='police' WHERE id BETWEEN 14 AND 17
SELECT * FROM person
删除
删除person表中一定范围的数据
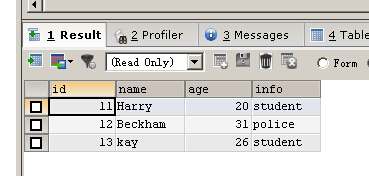
DELETE FROM person WHERE id BETWEEN 14 AND 17
SELECT * FROM person
如果要删除表的所有记录可以使用下面的两种方法
##方法一
DELETE FROM person
##方法二
TRUNCATE TABLE person
跟SQLSERVER一样,TRUNCATE TABLE会比DELETE FROM TABLE 快
MYISAM引擎下的测试结果,30行记录



跟SQLSERVER一样,执行完TRUNCATE TABLE后,自增字段重新从一开始。
################################
INSERT IGNORE INTO person(id,NAME,age,info)
SELECT id,NAME,age,info FROM person_old;
SELECT * FROM person
TRUNCATE TABLE person
INSERT IGNORE INTO person(NAME,age,info) VALUES ('amy',12,'bb')
SELECT * FROM person

当你刚刚truncate了表之后执行下面语句就会看到重新从一开始
SHOW TABLE STATUS LIKE 'person'

总结
这一节介绍了MYSQL里的的插入、更新和删除,并且比较了与SQLSERVER的区别,特别是MYSQL里插入语句的灵活性
刚刚开始从SQLSERVER转过来可能会有一些不适应
如有不对的地方,欢迎大家拍砖o(∩_∩)o